On the journey to cloud adoption we often face the less glamorous task of designing an organisation-wide tagging policy. Although this seems like a straight forward task, it often becomes an area of contention as each function and governing body within the organisation strives to influence the taxonomy of the tagging policy for the cloud environment such as AWS.
Furthermore we must also consider that tagging in a dynamic continuously delivered cloud environment is vastly different to the traditional IT Asset Management.
In order to reconcile business requirements we can examine identification and tagging of cloud resources through several business and technology perspectives.
Cost Management
Costs relating to consumption of cloud services should be identifiable and directly attributable to a business Cost Center for cost allocation and charge-out.
The most direct approach to address this requirement is to simply include a Cost Centre tag as a mandatory requirement across all resources. However, we should consider if the billing and reporting systems have additional granularity capabilities to allow quering and correlation of data with cost centres and other sources of information such as Application or Project.
It is also important to be able to differentiate running costs for each distinct version, build or branch of a deployed application. In doing so, it allows for the products owners and developers to effectively estimate, size and understand the applications resource requirements for each particular environment. In addition to this, when branches are clearly associated to JIRA issues as part of the development lifecycle it allows the team responsible to align the developer costs of a feature directly to the cloud platforms resource cost metrics, providing a clear total cost of feature development.
For example, applications with significant compute requirements like a HPC cluster regularly benefit from identification of cost variation between different versions of the software which may have introduced optimisations and different instances types.
Monitoring
Given the almost infinite resources available in cloud platforms today, developers are enabled to rapidly deploy multiple numbers of application stacks in parallel. As these application can contain a wide variety of different resource types it is important to ensure that each component of an application build is easily identifiable and linked to provide a holistic monitoring profile.
For example monitoring information for an application that includes 4 EC2 instances, 1 managed RDS service and 1 SQS Queue should be aggregated to a single view or dashboard by identifying these resources with a set of common tags laid down by your deployment pipeline. In doing so, you will also get an optimal user experience when working with cloud native monitoring products such as Datadog, which does it’s resource discovery and filtering using this method.
Incident Response
During an incident it is important to quickly identify resources affected. A strong tagging policy will result in the security team being able to rapidly identify the owners of the application and underlying resources and look to provide automated notifications to the application specific escalation group if/when they have been detected.
Constraints
Although most of the public cloud platforms provide a mechanism for assigning tags to resources, it is important to be aware that the availability of tagging functionality varies between each vendor and service. As such it is possible that some of the services may only support small number of tags (if any).
In a cloud native environment we should expect tags to be applied to the resources deployed where-ever possible as retroactively applying tags to running resources is a costly operation in API calls across the platform as well as in people hours as this will require extensive time to develop tools, test and apply changes.
Designing Tagging Policy
When designing a tagging policy it is important to keep the number of mandatory tags to a minimum, relying on external sources for organisation specific metadata. Sources such as Enterprise CMDB and application registers are excellent sources for such information.
In the below example we will demonstrate how an extensive set of mandatory metadata presented by a client to allow them to clearly understand and track the ownership of deployed cloud resources was evaluated and represented as a simple set of tags that were applied across the entire environment.
| Tag | Tag Key | Tag Value |
|---|---|---|
| Business Unit | BU | Engineering |
| Project | PROJECT | Icarus |
| Applicaiton Id | APP | IC001 |
| Environment | ENV | NONPROD |
| Branch | BRANCH | master |
| Build | BUILD | 12 |
| Cost Centre | COST | EN111000 |
| RTO | RTO | 4 |
| RPO | RPO | 1 |
| Criticality | CRIT | 1 |
| Data Classification | DATA | Private |
| Owner | OWNER | support@example.com |
Application components in Enterprise environments can be generally classified hierarchically, starting from the top-level business unit all the way down to the build/version number that signifies a single deployment of the application in an environment. Information such as Business Unit, Application Portfolio/Project and Application Id are generally assigned by the business as part of an ITSM Service Catalog management process.
Organisations entering Cloud from existing on-premises environments often have some maturity around the practices of IT Asset and Configuration management and as such have strong governance processes around assignment of assets to business units, locations and individuals. This information is generally stored in a central configuration management database (CMDB).
To reduce the complexity and increase robustness of the tagging policy, we can adopt data modelling practice and examine the relationships and cardinality between individual attributes, similar to the normalised database schema design process.
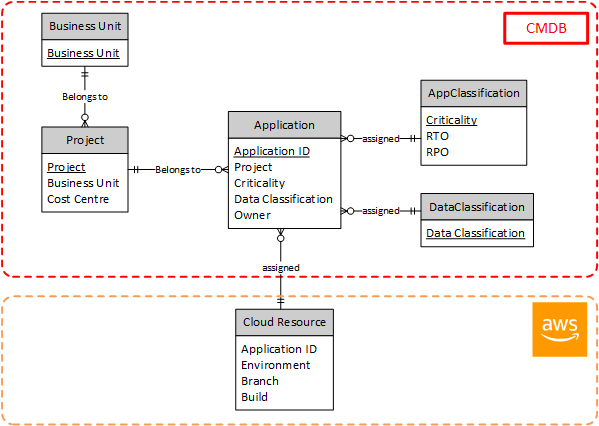
As demonstrated in the diagram above, We were able to achieve a minimal mandatory tagging structure through a deeper understanding of the of client’s processes and systems, leveraging more appropriate sources of “truth” for organisational metadata taxonomy.
| Tag | Tag Key | Tag Value |
|---|---|---|
| Applicaiton ID | APP | IC001 |
| Environment | ENV | NONPROD |
| Branch | BRANCH | master |
| Build | BUILD | 12 |
Conclusion
As demonstrated above, By removing complexity from the tagging structure we are able to leverage cloud native principles of immutable infrastructure, ensuring that the tags applied at the deployment stay throughout the lifecycle of the deployed resources, without the need to update tags mid-cycle to accommodate reporting requirements.
Consider the following guiding principles when designing a tagging policy for an enterprise:
- Keep the mandatory tags to a minimum - do not include superfluous information which may be derived from other tags or other external sources
- Be aware of capabilities of the billing and reporting systems - does the billing and reporting system allow the use of lookup tables and external sources?
- Do not overengineer tagging requirements, maintaining view of purpose and perspectives - do not include tags for information that “may” become useful.
- Focus on the business and regulatory perspectives - there is no point adding tagging information which does not address customers requirements, whether its financial, security or compliance.
- Define a schema - If the organisation does not already have a functioning CMDB, it is worth implementing a relational schema to support onboarding, off-boarding governance process for applications in a cloud environment.